This page contains a word sense disambiguation (WSD) approach based on the word sense inventories induced by the JoBimText project. The distinctive feature of this WSD model is that it is at the same time unsupervised, knowledge-free, and interpretable.
Jump to the online demo of the method.
Contents
Description of the model
The current trend in NLP is the use of highly opaque models, e.g. neural networks and word embeddings. While these models yield state-of-the-art results on a range of tasks, their drawback is poor interpretability. On the example of word sense induction and disambiguation (WSID), we show that it is possible to develop an interpretable model that matches the state-of-the-art models in accuracy. Namely, we present an unsupervised, knowledge-free WSID approach, which is interpretable at three levels: word sense inventory, sense feature representations, and disambiguation procedure. Our experiments with this model show that our model performs on par with state-of-the-art word sense embeddings and other unsupervised systems while offering the possibility to justify its decisions in human-readable form.
Our method tackles the interpretability issue of the prior methods; it is interpretable at the levels of (1) sense inventory, (2) sense feature representation, and (3) disambiguation procedure. In contrast to word sense induction by context clustering (Schutze (1998), inter alia), our method constructs an explicit word sense inventory. The method yields performance comparable to the state-of-the-art unsupervised systems, including two methods based on word sense embeddings. At this page, you will find a live demo of several pre-trained models of our approach.
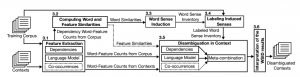
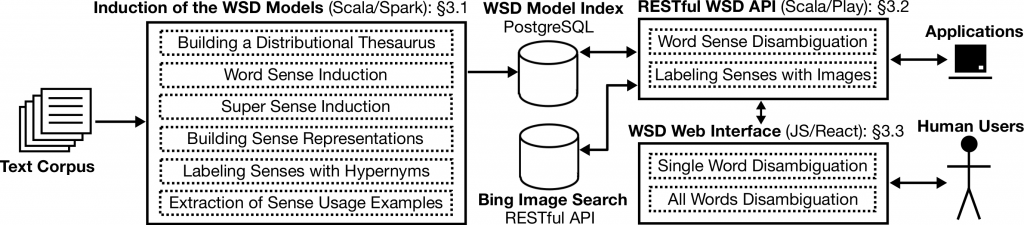
The figure above presents the outline of our unsupervised interpretable method for word sense induction and disambiguation, highlighting the main steps of our approach. The figure below presents the system from the software architecture angle. More details are available in the publication listed below.
The original publications
On this page, we describe our WSD system, as described in the following papers:
- Panchenko A., Marten F., Ruppert E., Faralli S., Ustalov D., Ponzetto S.P., Biemann C. Unsupervised, Knowledge-Free, and Interpretable Word Sense Disambiguation. In Proceedings of the Conference on Empirical Methods on Natural Language Processing (EMNLP 2017). 2017. Copenhagen, Denmark. Association for Computational Linguistics
- Panchenko A., Ruppert E., Faralli S., Ponzetto S. P., and Biemann C. (2017): Unsupervised Does Not Mean Uninterpretable: The Case for Word Sense Induction and Disambiguation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL’2017). Valencia, Spain. Association for Computational Linguistics.
Online demos
Web applications
The main demo which is related to the publications described above is the Unsupervised, Knowledge-free, and Interpretable WSD system which is able to perform all word sense disambiguation of input texts. In addition, you can browse through sparse graphs of related words, induced word clusters and the context clues of senses use the JoBimViz system. Finally, the Serelex system provides graph-based visualization of the ego-netoworks of the semantically related words related words.
APIs
You can perform word sense disambiguation using our method using the RESTful API. The web application for WSD described above relies on the same API, so the classification results observed in the web interface are the same as obtained using this API.
Here is a sample disambiguation of the word “Java” in the context “Java is an object-oriented programming language, developed by Sun Microsystems, Inc.land.” using the model “ensemble”:
curl -H "Content-Type: application/json" -X POST -d '{"context":"Java is an object-oriented programming language, developed by Sun Microsystems, Inc.","word":"Java", "model": "ensemble"}' http://ltbev.informatik.uni-hamburg.de/wsdapi/predictSense
The output is a JSON with the context features used to represent the input context and the predictions ie the list of most relevant word senses of the target word to the context:

The “predictions” is an array with predictions ranked by relevance (the confidence score for each prediction is available). The structure of each prediction is like this:

Other models include ‘simwords’, ‘clusterwords’, ‘hybridwords’, ‘random’, ‘mostfreq’, ‘cosetsrandom’, ‘cosetsmostfreq’, ‘cosets2krandom’, ‘cosets2kmostfreq’, ‘legacydeps’, ‘cosets’, ‘cosets2k’, ‘cosets2kcluster’, ‘cosetscluster’, ‘experimentalensemble’. See the web demo for examples.
To disambiguate words for all words in a sentence the method predictSense can be called simply for each word in the sentence. It makes however usually more sense disambiguate only nouns or named entities. To automatically detect the list of nouns and entities in an input context use the following method:
curl -H "Content-Type: application/json" -X POST -d '{"sentence":"Java is an object-oriented programming language, developed by Sun Microsystems, Inc."}' http://ltbev.informatik.uni-hamburg.de/wsdapi/detectNamedEntities
The output of the method is a list of the named entities. See an example for the sentence “Java is an object-oriented programming language, developed by Sun Microsystems, Inc.” is presented below:

To use the model which is described in the original paper you need to use the API endpoint presented below. This is different from the default API used in the examples above. Note that the set of available models for this API is also different. This endpoint support three models: fine-grained inventory “depslm5”, medium-grained inventory “depslm3”, and coarse-grained inventory “depslm2” or simply “depslm”. The coarse-grained inventory is the default inventory.
curl -H "Content-Type: application/json" -X POST -d '{"context":"Ruby is a red gemstone that varies from a light pink to a blood red, a variety of the mineral corundum (aluminium oxide).", "word":"ruby", "featureType": "depslm"}' http://ltmaggie.informatik.uni-hamburg.de/wsd-server/predictWordSense
Data
Below you can find the models in the CSV format for download used in our experiments. The files were computed on a dump from the English Wikipedia (see details in the paper).
Sense inventories
This archive contains 3 inventories (coarse, medium, and fine-grained) induced automatically from text using the ego-network graph clustering algorithm. Various granularities are obtained varying the connectivity of the ego-network (see the paper for details).
Context features
- Dependency features. This archive contains weighted word-feature combinations and includes their count and an LMI significance score. The dependencies were obtained using the Stanford PCFG parser.
- Features based on the language mode. This archive contains all n-grams up to n=3.
Graph of Feature Similarities
This archive contains a graph of syntactic context features. This similarity graph can be used for context expansion (see the paper for details).
Zenodo
All the datasets are also available at the Zenodo hosting for scientific datasets.
Software
The code used to conduct experiments presented in the paper is available as the part of the JoBimText framework under the “contextualization” namespace. The binary releases of the JoBimText software are available at the sourceforge. The models used in combination of this software are listed below.
The WSD server package is available on GitHub: WSD-Server
For further instructions on how to reproduce the experiments please contact Eugen Ruppert.