Multi-Word Support
The JoBimText web demo graphical user interface has been extended to feature multi-word JoBimText models. The user can choose the desired token length of the multiwords (Jo-length) he wants to select and select the multiwords using horizontal bars that span the desired tokens.
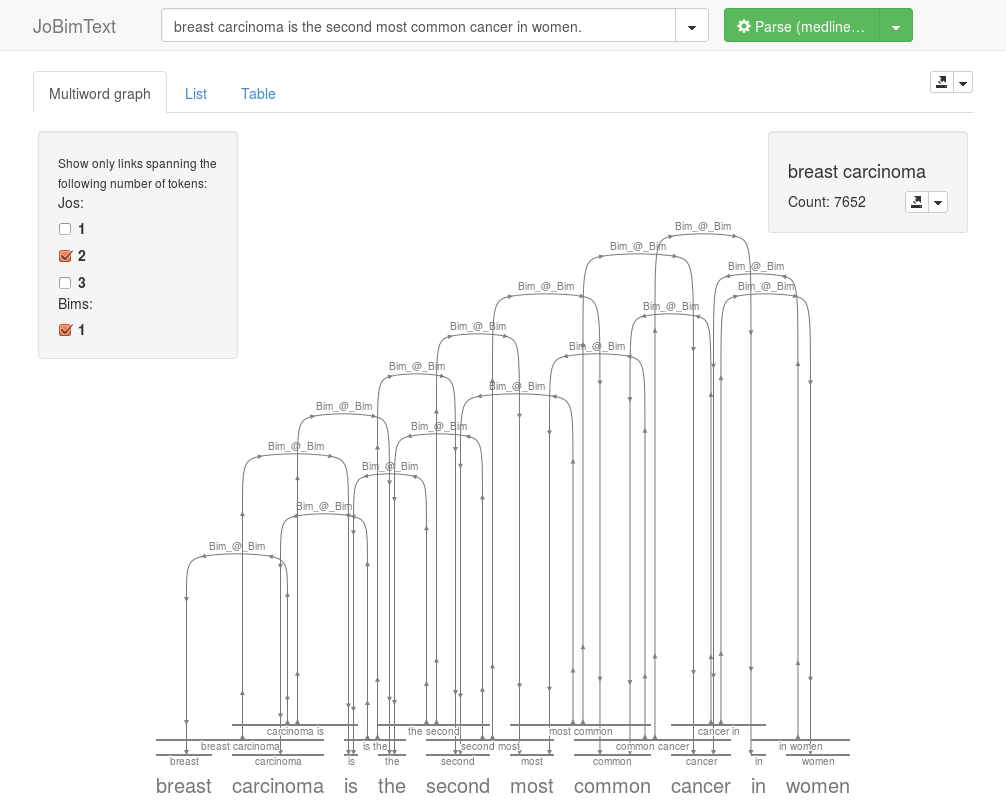
There are multiple views available for different presentation purposes: Graph, List and Table. Furthermore, the corpus count of the selected (multi-)word is now displayed prominently.
To try it out, go to the web demo site and select the “medline” dataset using the green dropdown selector at the top. Then you can see the visualiziation by entering a sentence and clicking on “Parse (medlineTrigram)”.
Medline Multi-Word Dataset
We have computed a Medline JoBimText model which is available directly within the demo.
Multi-word items with up to 3 tokens can be used via the graphical interface or the API. The specialty of this model is that similarities were computed among Jos lengths of 1 to 4 tokens. Thus, e.g. breast carcinoma (2 tokens) is not only related to breast cancer (2 tokens), but also to carcinoma of the breast (4 tokens) or melanoma (1 token).
This versatility of this model makes provides many advantages for life science and medical applications.